这是 UESTC 网络算法基础课程的 Project 1 实现。
关于环境的搭建,请参考:Mininet + RYU SDN 开发环境搭建 - Nativus' Space (naiv.fun)
代码仓库:Nativu5/Network_AlgoLab (gitee.com)
项目目标
- 在 Mininet 上搭建一个 20 个节点的网络,每个网络节点下挂一个主机;
- 使用 Ryu 连接 Mininet 中的交换机,并将拓扑读出来进行可视化展示;
- 在 Ryu 上实现深度优先遍历算法,并找出任意两个主机间的最短路和最长路;
- 使用最长路来配置任意两个主机间的通信连接;
- 将配置通的业务在可视化平台上进行展示。
实现思路
该部分代码仅作为配合讲解而摘录,具体的完整代码实现请参考代码仓库。
1. 拓扑存储
图的存储可以利用邻接矩阵、邻接链表、链式前向星等数据结构,但为了方便后期的可视化,我们直接使用了 NetworkX。NetworkX 是一个用于创建、操作、研究复杂网络的结构和功能的 Python 软件包,可以方便地实现图的存储和可视化,因此本项目选择在 NetworkX 的 DiGraph 类基础上,实现 Topo 子类,用于拓扑的存储。
class Topo(nx.DiGraph):
"""
网络拓扑,继承自 networkx.DiGraph
"""
def __init__(self):
super().__init__()
warnings.filterwarnings("ignore", category=UserWarning)
self.plot_options = {
"font_size": 20,
"node_size": 1500,
"node_color": "white", # 节点背景颜色
"linewidths": 3,
"width": 3,
"with_labels": True
}
self.pos = nx.spring_layout(self)
plt.figure(1, figsize=(18, 14))
plt.ion()虽然交换机间的连接是双向的,但由于我们在配置时需要交换机的端口信息,所以在本项目中,我们用两条有向边表示实际拓扑中的一条无向边,每条边额外记录本条链路的源端口信息。
# 保存链路信息,加入双向边(两条单向边),port 为 src 的发送端口
all_links = copy.copy(get_link(self))
self.topo.add_edges_from(
[(l.src.dpid, l.dst.dpid, {"port": l.src.port_no}) for l in all_links])
self.topo.add_edges_from(
[(l.dst.dpid, l.src.dpid, {"port": l.dst.port_no}) for l in all_links])2. 拓扑发现
为了实现数据包的最长路传递,我们需要控制器具备发现拓扑的能力,在此基础上我们才能实现搜索算法。
拓扑发现依赖于 RYU 的 --observe-links 参数,即控制器自动向网络中下发 LLDP 帧用于发现链路。利用这一特点,我们编写函数处理交换机进入消息(SwitchEnterEvent),调用 RYU 相关接口获取交换机间的链路信息,并将其存储到上述 Topo 对象中。
由于链路发现需要一定的时间,交换机进入消息可能出现多次,所以我们在每次收到交换机进入消息时都要清除历史数据,以免旧数据造成混乱。同时,每次拓扑发现完成后,我们都会调用 NetworkX 的 Draw 方法,在屏幕中显示当前已经发现的交换机拓扑。
3. DFS 算法搜索所有路径
我们从起点交换机节点 (src) 开始 DFS。每次调用 DFS,我们检测当前节点是否为终点交换机节点 (dst)。
如果到达终点交换机,我们将当前路径 (cur_path) 保存到路径结果集合 (all_paths) 中并返回递归的上一层函数;
如果当前未到达终点交换机,我们遍历当前节点的所有邻居,如果该邻居未被访问,则标记该邻居并将其加入路径,同时递归调用DFS。DFS运行完毕返回后,我们移除其标记,并将其从当前路径中删除,实现 DFS 的回溯,以便下一步遍历其他节点。(见图 1 DFS算法流程图)
def dfs(self, u: int, dst: int, vis: 'dict[int, bool]', cur_path: 'list[int]', all_paths: 'list[list[int]]'):
"""
DFS 递归遍历所有路径
"""
if u == dst:
all_paths.append(cur_path.copy())
return
for v in self.neighbors(u):
if not vis[v]:
vis[v] = True
cur_path.append(v)
self.dfs(v, dst, vis, cur_path, all_paths)
cur_path.pop() # 回溯
vis[v] = False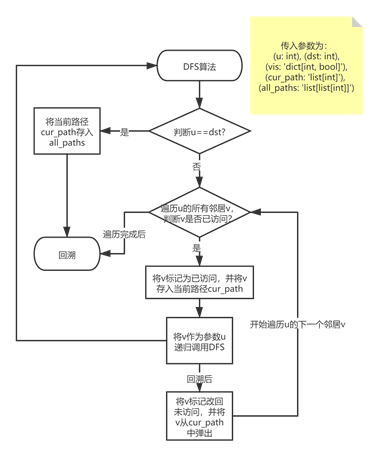
DFS 调用完成后,从起点到终点的全部路径都已经被存入路径结果集合中,只需遍历集合,比较路径的长度,即可得到起点和终点间的最长路径与最短路径。
self.dfs(src, dst, vis, cur_path, all_paths)
print("Found {} paths:".format(len(all_paths)))
shortest_path = all_paths[0]
longest_path = all_paths[0]
for path in all_paths:
if(len(path) > len(longest_path)):
longest_path = path
if(len(path) < len(shortest_path)):
shortest_path = path
print("Shortest path:", shortest_path,
"length:", len(shortest_path), sep=' ')
print("Longest path: ", longest_path,
"length:", len(longest_path), sep=' ')4. DFSController 控制器
控制器 DFSController 是继承自 RyuApp 的子类。控制器启动后,从 Mininet 中异步接收、处理和发送 OpenFlow 协议的消息。(见图 2 OpenFlow通信过程)
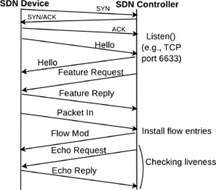
本项目中控制器处理以下类型的消息:
- OFPT_FEATURES_REQUEST 消息。该消息被控制器用来识别交换机并读取其规格。本项目中,控制器在接收到交换机的 OFPT_HELLO 消息后,发送 OFPT_FEATURES_REQUEST 消息以协定双方通信使用的 OpenFlow 版本,同时下发 Miss Table 流表,使得交换机能够将未来收到的无法匹配的数据包发送给控制器。
- OFPT_FLOW_MOD 消息。控制器通过发送OFPT_FLOW_MOD消息,对流表进行修改。
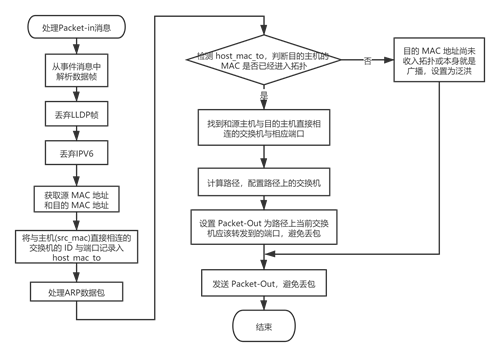
OFPT_PACKET_IN 消息。当数据通路 (Datapath) 接收到数据包时,并且无法与初Miss Table之外的流表匹配时,会使用OFPT_PACKET_IN消息将其发送到控制器。流程图见图 3 处理 Packet-in 消息。
![图 3 处理 Packet-in 消息]()
图 3 处理 Packet-in 消息 控制器从消息中解析出交换机无法匹配的数据包,判断其协议类型。若为 LLDP 帧,则丢弃(LLDP 仅用于 RYU 内置的 API 发现链路,我们无需对其进行处理);若为 IPv6 包,则丢弃(旧版本的 Mininet 存在一些问题,即使网络中的主机都仅使用 IPv4,网络中也会出现 ICMPv6 数据包,为避免不必要的麻烦,一律做丢弃处理)。
对于其他的数据包,我们解析其源 MAC 地址 (src_mac) 和目的 MAC 地址 (dst_mac)。源MAC地址保存在 host_mac_to 中,其意义是记录与主机 (src_mac) 直接相连的交换机的 ID 与端口。
随后,我们需要判断该数据包是否为 ARP REQUEST。如果该ARP数据包是首次抵达该交换机,我们将其保存在 ARP 历史记录 (arp_history) 中;如果检查 ARP 历史记录后发现该数据包已经出现过,我们将其丢弃。原因是,ARP REQUEST 会在网络内进行广播,而我们的网络拓扑中存在环路,并且交换机没有运行任何生成树协议 (STP) 消除冗余链路,很容易出现 ARP 风暴,进而破坏网络的正常运行。为了消除广播风暴的同时保证 ARP 协议的正常工作,我们引入了 ARP 历史记录进行判断。
接下来,检查目的 MAC 地址是否在 host_mac_to 中,从而判断目的主机 (dst_mac) 是否已经进入拓扑。若目的 MAC 已经进入拓扑,说明从源主机到目的主机的起点交换机和终点交换机都已找到。于是调用路径搜索函数,通过 DFS 算法计算路径。获取路径后,将路径打印在控制台中并进行可视化展示,同时向最长路径上的交换机下发流表,配置数据包的最长路传递。
最后,设置 out_port 为当前交换机应该转发到的端口,避免丢包。若路径已经配置完毕,则按照路径转发到相应端口。若目的 MAC 地址尚未收入拓扑或本身就是广播地址,设置为泛洪。
# 丢弃 LLDP 帧 if eth.ethertype == ether_types.ETH_TYPE_LLDP: return # 丢弃 IPV6 if eth.ethertype == ether_types.ETH_TYPE_IPV6: return # 获取源 MAC 地址和目的 MAC 地址 dst_mac = eth.dst src_mac = eth.src # self.logger.info( # "From {}:{} {} packet in ({} -> {})".format(dpid, in_port, eth.ethertype, src_mac, dst_mac)) # host_mac_to 记录与主机(src_mac)直接相连的交换机的 ID 与端口 if src_mac not in self.host_mac_to.keys(): self.host_mac_to[src_mac] = (dpid, in_port) # 处理 ARP 数据包 if eth.ethertype == ether_types.ETH_TYPE_ARP: arp_pkt = pkt.get_protocol(arp.arp) assert isinstance(arp_pkt, arp.arp) if arp_pkt.opcode == arp.ARP_REQUEST: # 这里处理的是 ARP 请求消息,因为 ARP 回复时 src 和 dst 必定已经加入拓扑 if (datapath.id, arp_pkt.src_mac, arp_pkt.dst_ip) in self.arp_history and self.arp_history[(datapath.id, arp_pkt.src_mac, arp_pkt.dst_ip)] != in_port: # 打破 ARP 循环,避免引发 ARP 风暴 return else: # 记录 ARP request 历史信息 self.arp_history[( datapath.id, arp_pkt.src_mac, arp_pkt.dst_ip)] = in_port # 检测 host_mac_to,判断目的主机的 MAC 是否已经进入拓扑 if dst_mac in self.host_mac_to.keys(): # 找到和源主机直接相连的交换机 src_switch = self.host_mac_to[src_mac][0] # 找到和源主机直接相连的端口 first_port = self.host_mac_to[src_mac][4] # 找到和目的主机直接相连的交换机 dst_switch = self.host_mac_to[dst_mac][0] # 找到与目的主机直接相连的交换机的端口 final_port = self.host_mac_to[dst_mac][5] # 计算路径 path = self.topo.search_path( src_switch, dst_switch, first_port, final_port) assert len(path) > 0 # 配置路径上的交换机 self.configure_path(path, src_mac, dst_mac) out_port = None # 设置 Packet-Out 为路径上当前交换机应该转发到的端口,避免丢包 for switch, _, op in path: if switch == dpid: out_port = op assert out_port # self.logger.info( # "From {}:{}, a {} packet in ({} -> {}), send to {}".format(dpid, in_port, eth.ethertype, src_mac, dst_mac, out_port)) else: # 目的 MAC 地址尚未收入拓扑或本身就是广播,设置为泛洪 out_port = ofproto.OFPP_FLOOD # self.logger.info( # "Unknown/Broadcast MAC address {}, flooding...".format(dst_mac))- OFPT_PACKET_OUT 消息。控制器需要通过数据通路发送一个数据包时,使用 OFPT_PACKET_OUT 消息。
其他问题
拓扑的可视化
注意,如果 Linux 的开发环境下没有 GUI,则需要通过 X11 Forward 等方式实现可视化,具体可以参考文章最开始环境配置部分中的链接。
项目要求能够可视化地展示拓扑发现和寻路结果,所以我尽可能地使得画面能够具有动态效果。最终的实现效果是拓扑会出现在一个固定的窗口中,随着拓扑的不断发现和路径的搜索而刷新,就好像放映一帧帧的动画。
具体的实现使用了 NetworkX 和 matplotlib.pyplot,实现时需要注意:
# Topo 类初始化时:
plt.figure(1, figsize=(18, 14))
plt.ion()# 拓扑发现时:
plt.title('Discovered Topology')
self.topo.pos = nx.spring_layout(self.topo)
nx.draw(self.topo, pos=self.topo.pos,
edgecolors="black", **self.topo.plot_options)
plt.show()
plt.savefig("Topo.png")
plt.pause(1)
self.logger.info('Topology image saved.')# 绘出路径
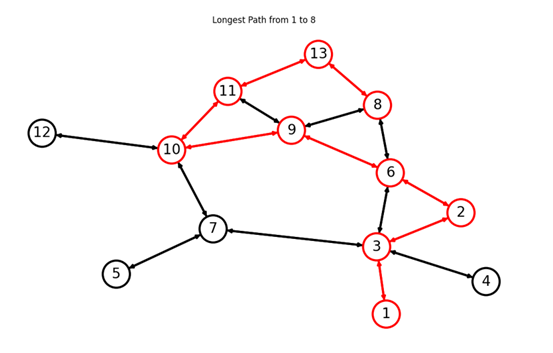
def draw_path(self, path: "list[int]"):
edge_to_display = []
for s1, s2 in zip(path[:-1], path[1:]):
edge_to_display.append((s1, s2))
edge_to_display.append((s2, s1))
edge_colors = [
"red" if e in edge_to_display else 'black' for e in list(self.edges)]
node_edge_colors = [
"red" if n in path else "black" for n in list(self.nodes())]
plt.clf()
plt.title("Longest Path from {} to {}".format(path[0], path[-1]))
nx.draw(self, pos=self.pos, edge_color=edge_colors,
edgecolors=node_edge_colors, **self.plot_options)
plt.show()
plt.pause(1)关于 NetworkX 和 pyplot 的文档请参考:
Software for Complex Networks — NetworkX 2.6.2 documentation
Matplotlib documentation — Matplotlib 3.5.1 documentation
测试和验证
测试和验证的基础是已经完全安装好了项目所需要的软件环境,比如 Mininet 和 Ryu。
首先需要先编写脚本生成一个 Mininet 网络。
from mininet.net import Mininet
from mininet.node import RemoteController, Host, OVSKernelSwitch
from mininet.cli import CLI
from mininet.log import setLogLevel, info
from mininet.clean import cleanup
def myNetwork():
net = Mininet(topo=None,
build=False,
ipBase='10.0.0.0/8')
info('*** Adding controller\n')
c0 = net.addController(name='c0',
controller=RemoteController,
protocol='tcp',
port=6633)
info('*** Add switches\n')
s1 = net.addSwitch('s1', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s2 = net.addSwitch('s2', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s3 = net.addSwitch('s3', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s4 = net.addSwitch('s4', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s5 = net.addSwitch('s5', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s6 = net.addSwitch('s6', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s7 = net.addSwitch('s7', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s8 = net.addSwitch('s8', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s9 = net.addSwitch('s9', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s10 = net.addSwitch('s10', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s11 = net.addSwitch('s11', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s12 = net.addSwitch('s12', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
s13 = net.addSwitch('s13', cls=OVSKernelSwitch, protocols=['OpenFlow13'])
info('*** Add hosts\n')
h1 = net.addHost('h1', cls=Host, ip='10.0.0.1',
defaultRoute=None, mac='00:00:00:00:00:01')
h2 = net.addHost('h2', cls=Host, ip='10.0.0.2',
defaultRoute=None, mac='00:00:00:00:00:02')
h3 = net.addHost('h3', cls=Host, ip='10.0.0.3',
defaultRoute=None, mac='00:00:00:00:00:03')
h4 = net.addHost('h4', cls=Host, ip='10.0.0.4',
defaultRoute=None, mac='00:00:00:00:00:04')
h5 = net.addHost('h5', cls=Host, ip='10.0.0.5',
defaultRoute=None, mac='00:00:00:00:00:05')
h6 = net.addHost('h6', cls=Host, ip='10.0.0.6',
defaultRoute=None, mac='00:00:00:00:00:06')
h7 = net.addHost('h7', cls=Host, ip='10.0.0.7',
defaultRoute=None, mac='00:00:00:00:00:07')
h8 = net.addHost('h8', cls=Host, ip='10.0.0.8',
defaultRoute=None, mac='00:00:00:00:00:08')
h9 = net.addHost('h9', cls=Host, ip='10.0.0.9',
defaultRoute=None, mac='00:00:00:00:00:09')
h10 = net.addHost('h10', cls=Host, ip='10.0.0.10',
defaultRoute=None, mac='00:00:00:00:00:10')
h11 = net.addHost('h11', cls=Host, ip='10.0.0.11',
defaultRoute=None, mac='00:00:00:00:00:11')
h12 = net.addHost('h12', cls=Host, ip='10.0.0.12',
defaultRoute=None, mac='00:00:00:00:00:12')
h13 = net.addHost('h13', cls=Host, ip='10.0.0.13',
defaultRoute=None, mac='00:00:00:00:00:13')
info('*** Add links\n')
# Every switch links one host:
net.addLink(s1, h1)
net.addLink(s2, h2)
net.addLink(s3, h3)
net.addLink(s4, h4)
net.addLink(s5, h5)
net.addLink(s6, h6)
net.addLink(s7, h7)
net.addLink(s8, h8)
net.addLink(s9, h9)
net.addLink(s10, h10)
net.addLink(s11, h11)
net.addLink(s12, h12)
net.addLink(s13, h13)
# Links between switches:
net.addLink(s1, s3)
net.addLink(s3, s2)
net.addLink(s2, s6)
net.addLink(s3, s6)
net.addLink(s3, s4)
net.addLink(s3, s7)
net.addLink(s7, s5)
net.addLink(s7, s10)
net.addLink(s6, s8)
net.addLink(s8, s13)
net.addLink(s8, s9)
net.addLink(s9, s10)
net.addLink(s10, s12)
net.addLink(s6, s9)
net.addLink(s10, s11)
net.addLink(s9, s11)
net.addLink(s11, s13)
info('*** Starting network\n')
net.build()
info('*** Starting controllers\n')
for controller in net.controllers:
controller.start()
info('*** Starting switches\n')
s1.start([c0])
s2.start([c0])
s3.start([c0])
s4.start([c0])
s5.start([c0])
s6.start([c0])
s7.start([c0])
s8.start([c0])
s9.start([c0])
s10.start([c0])
s11.start([c0])
s12.start([c0])
s13.start([c0])
info('*** Post configure switches and hosts\n')
CLI(net)
net.stop()
if __name__ == '__main__':
setLogLevel('info')
myNetwork()
cleanup()这个脚本会在图中生成一个具有 13 个交换机的网络,每个交换机下挂一个主机。写法十分简单粗暴、直白如话,可以根据需求仿照上面写法修改脚本来生成自己的 Mininet 网络。
运行 RYU 控制器,然后运行上述脚本启动 Mininet。注意,必须使用 --observe-links 选项,否则不能实现链路发现功能。
sudo ryu-manager DFSController.py --observe-links # 运行控制器
sudo python3 topo.py # 运行 Mininet
如果已经设置好了可视化的环境,这时会弹出 pyplot 窗口,显示拓扑,同时在拓扑发现完毕后,会在所在目录下生成 Topo.png 图片。
拓扑发现完成后屏幕暂时不再闪动,这时可以检查控制器打印的信息是否和 Mininet 设置的相同(例如检查节点数和链接数是否一致),如果无误可以测试寻路算法。在 Topo.py 启动的 Mininet 命令行中输入:
h1 ping -c 1 h2测试 h1 到 h2 的连通性,这个过程中屏幕会闪动,搜索出的路径会被标为红色,同时在命令行中打印出来。
一次性测试所有节点间的连通性:
pingall如果 Mininet 命令行中不出现 X 标记即说明连通性良好。
退出 Mininet,在 Mininet 命令行中输入:
exit推荐这种方式退出,原因是这样会自动清理 Mininet 的配置和关闭控制器,防止影响下次测试。
常见故障
- 链路发现结果不正确。可能需要多次测试,出现链路发现故障是正常的,一般重启 Mininet 可以解决。
环境启动异常。重置 Mininet 一般可以解决:
sudo mn --clean实在不行可以重启虚拟机。
后记
在听助教讲解和查看网上资料时,发现思路都是让 Controller 维护一个路由表,遇到 ARP 请求 Controller 下发指令让交换机进行应答。但我实现时没有这样做,原因是我认为这是一个二层的网络,交换机作为二层的设备不应该发送 ARP 数据包,Controller 能做的应当仅限于解析 ARP 数据包防止网络中出现 ARP 风暴而已……即,我倾向于让这个网络更加贴合传统的、现实的二层的网络。
关于这一点我咨询了老师,老师表示,旧的、传统的网络没有中心化的 Controller,不能实现根据 ARP 生成一个路由表控制所有交换机。但这里是一个 SDN 网络,既然有了 Controller 能够实现这样的功能,何乐而不为?
诚然,这样的做法可以减少 ARP 数据包对网络带宽的占用,对性能应当是有提升的。但是,也无形中加重了 Controller 的负担……这次实验启示我,面对新的技术应该有跳出原本思维定势的能力,脱离传统的做法去思考可能会获得一些更加优化的想法。
参考资料:
感谢两位队友的支持和帮助!